
Index Data for an EDM
The DLP indexer creates irreversible fingerprints of critical data structured in records with a consistent format and uploads them to Umbrella to establish a custom EDM Identifier. EDM Identifiers enable Umbrella to protect sensitive data by using data fingerprinting techniques as opposed to pattern matching techniques.
EDM Identifiers can be added to a Data Classification (see Manage Data Classifications) as custom identifiers; DLP rules that use these identifiers can monitor and/or block files that match the data you have indexed.
You need to run the DLP indexer in two different circumstances:
- When you initially create an EDM Identifier, you run the indexer on the data set you want to detect. This topic provides basic information for running the indexer, but for a description of the process to use the indexer within the context of creating an EDM Identifier, see Create an Exact Data Match Identifier. You cannot use the indexer to create an EDM Identifier without also performing the steps described in that topic.
- When the data set to be detected changes, you run the indexer to produce an updated version of the EDM Identifier. This process is described in Update the Indexed Data Set Periodically.
NOTE: To see a summary of the indexer options available, invoke the indexer with the -h option. (java -jar <directory-path>\dlp-indexer.jar -h.)
Table of Contents
- Prerequisites
- Run the DLP Indexer to Create an EDM Identifier
- Update the Indexed Data Set Periodically
- Troubleshooting
Prerequisites
- Full admin access to the Umbrella dashboard. See Manage User Roles.
- JVM version 17+
- You must download the indexer using the Umbrella GUI. See Step 6 in Create an Exact Data Match Identifier.
- Before running the DLP indexer you must generate an API Key and Secret using the Umbrella GUI. See Step 8 in Create an Exact Data Match Identifier.
NOTE: If you already have a key and secret generated for use with a previous run of the DLP indexer, you may use those.
- The indexer supports indexing source files with up to 55 million records. The exact records limit is determined by the total number of columns and how many of those are of alphanumeric type. The indexer will report the exact limit when attempting to load a file that exceeds it. If your dataset is larger than the limit, you need to split the records into multiple files. For errors received when indexing a large file, see Memory Tuning for DLP Exact Data Matching Indexer.
- The source data CSV file you index must meet the following requirements:
- A multi-term (multi-word) field can contain a maximum of 6 space-separated words.
- The data file must contain only 1 byte or 2 byte UTF-8 encoded characters.
- The first row of data must have between 1 and 50 fields and each row must have the same number of fields.
- The first row of data must specify the name of each field, and each value must be unique.
- Data in the second and ensuing rows must comply with the EDM field types and supported formats (See Exact Data Match Field Types.)
- The field names in the sample data template must match the field names in the actual data source file. The field names must appear in the same order in both files.
CAUTION: Do not create, edit, or view the source data CSV file using Microsoft Excel, as this may corrupt the file. Use a text editor.
NOTE: If any of the values provided in the source file to the DLP indexer fail to be validated as per the supported format, then the DLP indexer will skip that record and proceed with indexing the remaining records. The indexer also behaves in this manner for any records that may exceed the template-defined fields, and for empty rows or records with empty primary values. The DLP indexer generates messages reporting the position of any skipped records in the file.
Run the DLP Indexer to Create an EDM Identifier
When you create a new EDM Identifier, you need to run the DLP indexer on the data set to upload the first set of data records. For the full procedure to create an EDM identifier, see Create an Exact Data Match Identifier.
- Review the Prerequisites, especially:
- Be sure you have the API key and secret. (See Step 8 in Create an Exact Data Match Identifier.)
- Be sure you have the EDM Identifier ID. (See Step 7 in Create an Exact Data Match Identifier.)
- Run the indexer in a terminal window with the following command:
java -jar <directory_path>\dlp-indexer.jar -i "<directory_path>\<source-file>.csv"
-e <edm-template-id> -k <authKey> -s <authSecret>
Where:
- <directory_path>\dlp-indexer.jar —the relative path to the location of the DLP indexer
- "<directory_path>\<source-file>.csv" —the relative path to the csv spreadsheet with the actual data records
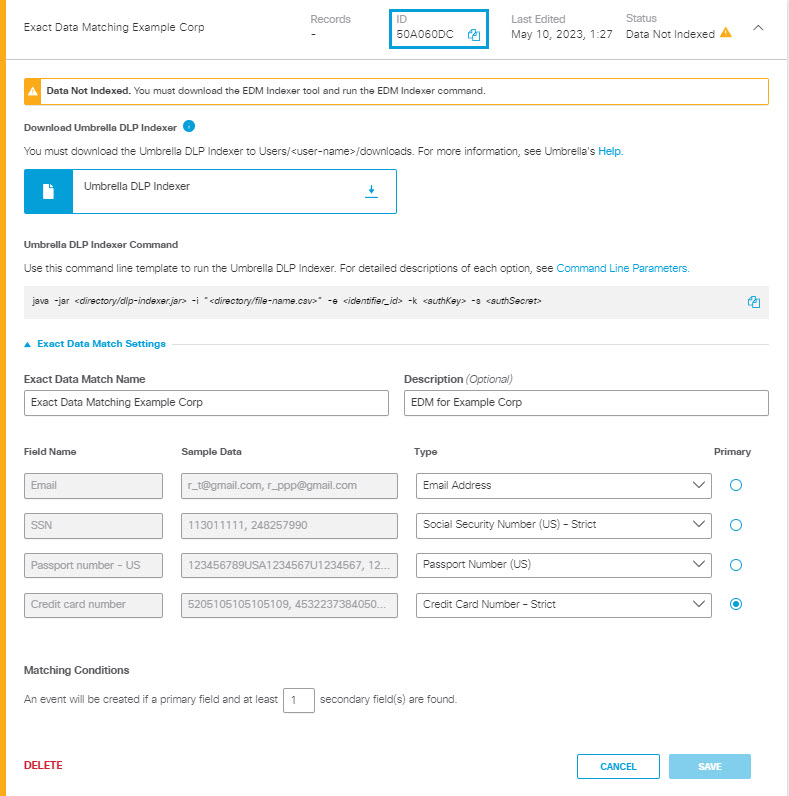
- <edm-template-id> —the ID of the EDM Identifier retrievable from the Umbrella UI using the copy icon shown in the following screenshot. (See also Step 7 in Create an Exact Data Match Identifier.)
- <authKey> —the API Key previously saved at Step 8d of Create an Exact Data Match Identifier.
- <authSecret> —the API Secret previously saved at Step 8d of Create an Exact Data Match Identifier.
If the indexer runs successfully, the exact data matcher will have a status of Data Indexed.
NOTE: When the EDM has a status of Data Indexed, you can add the EDM to a data classification but you can not edit the field types, primary field selection, or matching condition.
Update the Indexed Data Set Periodically
When your source data changes, the existing EDM Identifier on your configured policy must be updated to reflect the new data fingerprints. Using a script allows you to automatically rerun the DLP indexer periodically to update your source data to Umbrella without manually performing the initial procedure over again. After you rerun the DLP indexer with the updated version of the source file against the ID of your EDM Identifier, the DLP Policies configured with that EDM Identifier account for the most recent updates to your critical records.
- In a terminal window, set the the API Key and Secret previously used to index the identifier (saved in Step 8d of Create an Exact Data Match Identifier ) to the environment variables DLP_AUTH_KEY and DLP_AUTH_SECRET.
- Run the command to re-index the identifier as part of a periodically executed script or manually as needed:
java -jar <directory_path>\dlp-indexer.jar -i "<directory_path>\<source-file>.csv"
-e <edm_template-id> -k DLP_AUTH_KEY -s DLP_AUTH_SECRETWhere:
- \<directory_path>\dlp-indexer.jar —the relative path to the location of the DLP indexer
- "\<directory_path>\<source-file>".csv —the relative path to the csv spreadsheet with the actual data record.
- <edm-template-id> —the ID used to index the EDM Identifier originally.
Troubleshooting
If the indexer reports a failure, examine the output error messages to determine the problem.
If the indexer returns an error message that reads, "Error: A JNI error has occurred, please check your installation and try again," check the following:
- Confirm you have the latest version of the Java Development Kit installed.
- Confirm that you have your PATH system variable set correctly:
- Check the location where you have Java installed.
- For Windows this is normally C:\Program Files\Java\jdk-\bin
- For Linux this is normally /usr/java/jdk-<version-number>/bin
- Use the instructions here to set the PATH system variable appropriately for your operating system.
NOTE: If the data indexer fails to process the input file and returns a base64 encoded error code, provide that code to the Umbrella Support to assist you with troubleshooting.
Create an Exact Data Match Identifier< Index Data for an EDM > Exact Data Match Field Types
Updated over 1 year ago